مهندس مهدی غفاری
هر نسخه ای از دیتابیس شامل بهبودها و ویژگیهای جدید بسیار زیادی است که همین موضوع همیشه اشتیاق من رو برای نگهداری بهتر سرویس دیتابیس بالا نگه میداره
در کنار تمام بهبودها و ویژگیهای جدید جذاب و پر زرق و برق باید یادمون بمونه که هر نرمافزاری باگ داره مهم نیست اون نرمافزار توسط چه تیم یا کمپانی مدیریت شده باشه همیشه یادمون باشه جا برای داشتن باگ وجود داره
همیشه برای من دیتابیس و کارم مثل بچه ام بوده پس کوچکترین باگی رو اگه ببینم از حل موضوع کنار نخواهم اومد.
همونطور که قبلا نوشتم من از یک کلاستر ۳ نود همراه با ۴ دیتا گارد اکتیو پشتیبانی میکنم. زیرساخت من از گرید ۱۹.۳ و دیتابیس ام از نسخه ۱۲.۲ تشکیل شده.
داستان این باگ
نزدیک ۴ ماه پیش بود شخصی در گروه پیام داد که به مشکل زیر برخورد کرده
"در ورژن 12c به بالا automatic maintennace task ها رو باید روی CDB فعال کرد یا PDB ضمن اینکه روی PDB جاب Sql Tuning اجرا نمیشه (احتمالا باگ هست)"
موضوع اجرا نشدن جاب SQL Tunning در PDB برای من بسیار جالب بود.
در بررسی موضوع به دایکومنت زیر اشاره کردیم
Automatic SQL Tuning Advisor Task Does Not Run At PDB Level (Doc ID 2538576.1)
و با توجه به مستند زیر
و جمله زیر در این مستند
Automatic SQL Tuning Advisor runs only in the CDB root. See the SQL Tuning Advisor row in this table for information about data collected by Automatic SQL Tuning Advisor.
شاید از نظر هر ادمین دیگه ای بود کار تمام شده در نظر گرفته میشد اما برای من نه
از دوستمون آقای Seif که بنده رو از این باگ مطلع کرده بود درخواست کردم دلیل خود را برای این ادعا بیان کند و ایشون به باگ زیر اشاره کردند
Bug 29853847 : AUTOTASK JOBS NOT RUNNING ON 12.2.0.1 FOR PDB
این باگ با یک دستورالعمل دیاگ مشخص در پی اثبات این موضوع است که جابهای اتوماتیک پیش فرض اوراکل
در سطح pdb شروع میشوند اما واقعا اجرا نمیشوند.
پس با این دیاگ مشخصا یک باگ در اوراکل برای نسخه ۱۲.۲ ثبت شده است
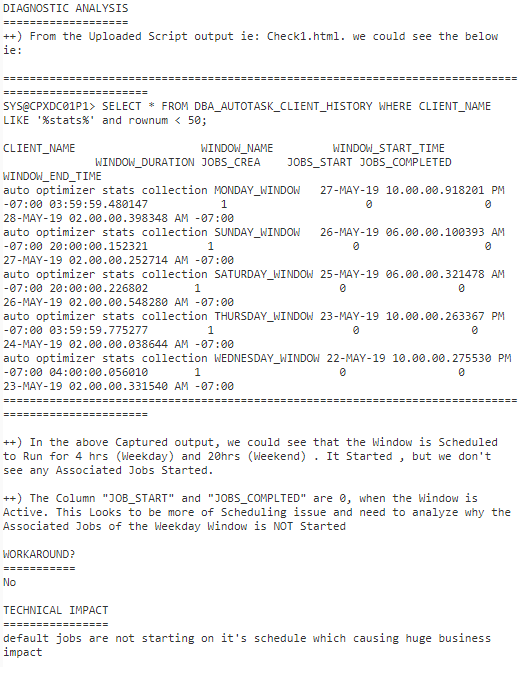
بعد از واضح شدن این موضوع برای من شروع به آنالیز در محیطهای تست و عملیاتی خودم کردم و با تعجب این مشکل را در نسخه ۱۲.۲ با آخرین PSU در محیطهای خودم مشاهده نکردم همچنین توضیحات زیر در صفحه باگ من رو برای بررسی بیشتر کار بیشتر و بیشتر علاقه مند میکرد. پس برای بررسی بیشتر کار ادامه دادم:

در ادامه بررسی متوجه شدم باگ شماره 29853847 با باگ 23296836 مشابه است پس قاعدتا باگ 29853847 بسته شده - در حقیقت باگ 29853847 به خاطر باگ 23296836 ایجاد میگردد پس بیس این باگ برابر باگ 23296836 است.
تو صفحه باگ 23296836 عنوان شده که ورژنهای زیر تحت تاثیر این باگ قرار دارند

همونطور که میبینید این باگ تنها در نسخه 20.1.0 و 19.4.0.0.190716 حل شده ولی چرا این مشکل اصلا به وجود میاد؟
در توضیحات اومده: برای پردازش PL/SQL notification ها صفهای AQ's Classic با جابهای DBMS Scheduler و با اسامی AQ$_PLSQL_NTFN_<TIMESTAMP> ثبت میشوند. هنگامی که مقدار پارامتر job_queue_process روی عددهای کم مثل ۱۰ پیکربندی میشه، ممکنه هیچ یک از کارهای AQ$_PLSQL_NTFN به وضعیت اجرا نرسه و همه اونها در وضعیت ثبت شده (Submitted) باقی بمونه. دلیل این موضوع ممکنه این باشه که ۱۰ تا جاب دیگه در حال اجرا هستش و تمام ۱۰ فضای خالی اشغال شده.
در این سناریو، اسلیوهای EMON که جابهای AQ$_PLSQL_NTFN رو ثبت میکنند، اطلاع ندارند که جابهای AQ Notification ثبت شده اند یا نه. در نتیجه، آنها به ثبت جابهای جدید ادامه میدهند گرچه تمام آنها در وضعیت Submitted میمانند. و ظرف مدت چند ساعت ما مشاهده میکنیم که هزاران یا میلیون ها جاب AQ$_PLSQL_NTFN_* در dba_scheduler_jobs به صورت submitted قرار دارند.
موضوع برای من بسیار جالب شد پس پارامتر job_queue_process را در محیط زیر برابر ۱۰ قرار دادم و موضوع را بررسی کردم
Database Apr 2020 Release Update : 12.2.0.1.200414
همونطور که فکر میکردم مشکل وجود داشت پس مشکل را با تست کیسها و آنالیزهای متفاوت به اوراکل گزارش دادم.
بعد از ایجاد درخواست و پیگیری های فراوان در مرحله توسعه و تست بعد از ۴ ماه دیشب پچ اون برای نسخه 12.2.0.1.200414 در دسترس قرار گرفت.
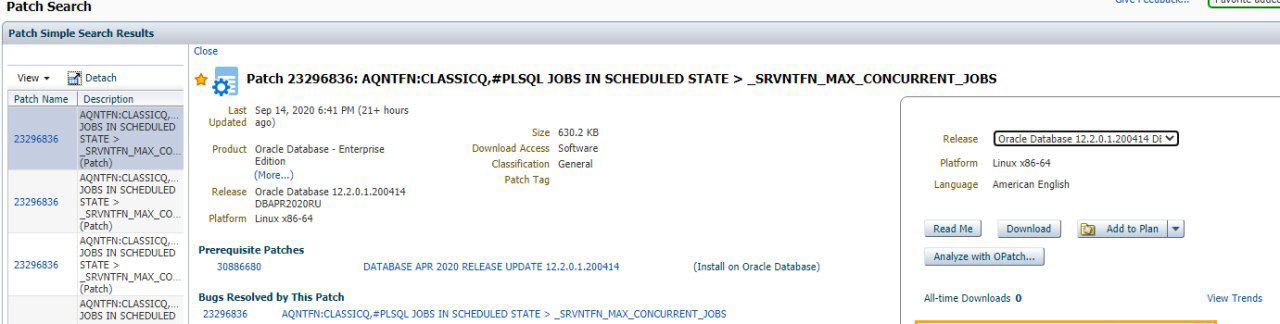
لازم به ذکره پچ اصلی ۱۹ روز پیش برای نسخه 12.1.0.2.0 در دسترس قرار گرفته بود

در نهایت اگر دنبال ادمین و یا مشاور با انگیزه برای پروژههای خود هستید میتونید اطلاعات تماس بنده رو از لینک
همچنین من مشتاقانه از پیشنهادات کاری به صورت job offer در شرکتهای اروپایی استقبال میکنم.
مشخصات
داشتم از ویژگی کلون گیری آنلاین PDBها (Cloning a Remote PDB یا در RMAN HOTCLONE) برای انتقال PDBها از سرور قدیمی به سرور جدید که از نسخه 12.1.0.1 به بعد ارائه شده بود طبق مقاله
محیط من شامل
سیستم عامل:
Oracle Linux Server release 8.4
دیتابیس سورس:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.13.0.0 with File System
دیتابیس مقصد:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.13.0.0 with File System ASM
طبق مقاله آقای Tim Hall ابتدا اتصال امون رو با rman به سرور اصلی و کمکی برقرار میکنیم (با این تفاوت که لاگ و دیباگ رو روشن میکنیم)
(در اینجا CDB1 سرور اصلی (سورس) و CDB2 سرور کمکی (auxiliary) است - اضافه کردن UR = A در TNS فراموش نشه!!)
rman target sys/<password-sys>@CDB1 auxiliary sys/<password-sys>@CDB2 log /tmp/pdb_clone.log trace /tmp/pdb_clone.trc debug
بعد از اتصال موفق دستور زیر رو برای شروع کلون گیری در rman اجرا میکنیم.
مشخصات
یک RAC سه نود بر روی اوراکل نسخه 12.2 داریم. مدتی بود در وقت های پیک کاری اپلیکیشن، با ویت ایونت gc current block 2-way و . و با مقدار بالا برخورد میکردم به نحوی که کارکرد اپلیکیشن رو مورد تاثیر خود قرار داده بود. از طرفی تمام موارد مرتبط با GC در کلاستر رو با دقت و وسواس بالا با توجه به آخرین Best Practiceها پیکربندی و بازبینی کرده بودم (به خصوص پارامترهای مرتبط با LMS مانند GCS_SERVER_PROCESSES) و با مانیتورینگ شبکه و سرعت Interconnect هام از سرعت و وضعیت خوب اونها مطمئن بودم همچنین با توجه به مشاهدات محیطی به این نتیجه رسیده بودم که در طول 2 ماه کارکرد اپلیکیشن تنها در انتهای بازه های پیک اپلیکیشن این مشکل دیده میشد پس این موضوع کنجکاوی من رو برای این که بفهمم مشکل کجا بود بیشتر کرد.
تو بررسی هام از طریق Memory Advisor در Enterprise Manager متوجه شدم که در این روزها فضای shared pool به طرز قابل توجهی بالا میره و فضای buffer cache بسیار کوچیک میشه پس با این فرض همه چیز منطقی به نظر میومد. چون با رشد فضای shared pool فضای کافی برای buffer cache نبود.

زمانی که سیستم در وضعیت و پرفورمنس مناسب قرار داشت
مشخصات
- انجمن ادبیات داستانی ایده
- heidar119
- shariandressshop
- partynightdressshop
- marmar78
- فروشگاه اینترنتی زیر زیر قیمت ها
- raouf1398
- .
- بلاگی برای فایل ها
- اَرْغَنوٓنْ
- refreshtip
- marketba
- saeed1991
- داستانها و نکات قرآنی
- mansari
- babagolzade
- دانلود جزوه pdf
- ubook
- پيش به سوي داشتن مدرسه اي بهتر
- چهار سوی علم
- برای مهدی
- radikal
- text021dis2006love
- 058fdffdf69iu
- 0584gfyth9iu
درباره این سایت